요즘 Reactive로 개발을 하면서 이것저것 온갖 고난을 맛봤다.
괜히 도입을 했나 싶을 정도로 디버깅도 어렵고 값 추적이 쉽지 않다.
롤백할까도 많이 고민했었다
자바만 하다 보니 비동기에 대한 이해도 부족하고 왜 이렇게 돌아가는지 이해도 잘 안 되는 거 같은데
어느 정도 정리가 된 거 같아 글을 써본다.
Reactive 도입의 필요성?
전통적인 프로그래밍은 많은 양의 데이터를 실시간으로 처리하는 데 어려움을 겪을 수 있다.
이때 전통적인 프로그래밍이란 Spring MVC인데
전통적인 Servlet 기반의 Web Application Framework이며,
요청 당 스레드를 할당하여 동작한다.
반면, Spring WebFlux는 Reactive Streams를 기반으로 한
Non-Blocking IO 모델을 사용하여 요청 처리를 한다.
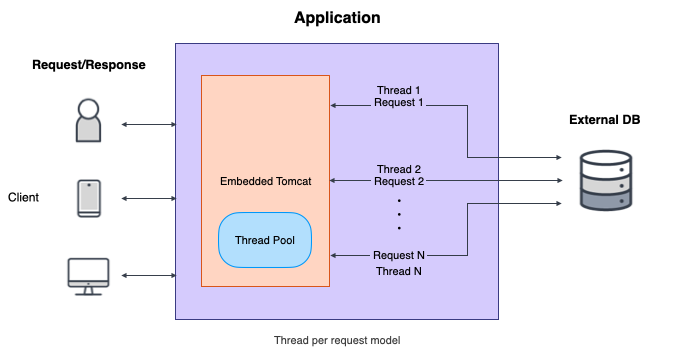
spring mvc는 요청 하나의 응답이 길어지게 되면 스레드 하나가 계속 붙잡히고
요청이 많아지면 많아질수록 쓰레드들이 계속 밀리게 되면서 풀이 고갈되어 전체 시스템에 문제가 발생하게 된다.
Reactive Programming 모델은 적은 스레드로 높은 처리량을 달성할 수 있다.
이는 매우 높은 부하가 예상되는 경우나 매우 빠른 응답이 필요한 서비스에서 특히 유용하다.
물론 mvc에서도 서버 스펙이 좋다면 많은 트래픽을 감당할 수 있지만
제한된 리소스를 효율적으로 써야 하는 서비스에는 적합하지 않을 수 있다.
리액티브 프로그램이란?
Reactive programming 비동기 데이터 스트림의 개념을 기반으로 하는 프로그래밍 패러다임
옵저버 패턴에 기반을 두고 있으며 새로운 데이터가 사용 가능할 때 알림을 받는다.
서비스에서 외부 API를 호출하거나 DB 등의 외부 자원에 액세스 하는 경우,
블로킹 호출을 기다리는 동안 스레드는 대기 상태가 되며, 서비스의 지연 시간이 증가한다.
반면 Reactive Programming 모델에서는 콜백을 사용하여 외부 자원 호출을
비동기적으로 처리하므로 지연 시간을 줄일 수 있고 마이크로서비스 아키텍처에서 사용하기에 적합하다.
Spring에서는 Reactive Stack을 다음과 같이 제공한다.

이 접근 방식은 다음과 같은 몇 가지 이점을 제공한다:
Improved scalability - 애플리케이션이 대량의 데이터와 요청을 비동기식으로 처리하여 처리할 수 있다.
Improved responsiveness - 애플리케이션은 데이터를 비동기적으로 처리하여 사용자 요청 및 이벤트에 더 빨리 응답할 수 있다.
Improved resilience - 오류 처리를 위한 내장 메커니즘을 제공하여 오류 및 오류를 보다 우아하게 처리할 수 있다
Reactive와 기존 mvc의 차의 점
차이점 알려면 동기 비동기, 블로킹 논블로킹을 이해해야 한다.

동기 블로킹
- 클라이언트가 서버를 호출한다
- 블로킹 : 서버가 제어를 가져간다
- 동기 : 클라이언트는 반환값 기다림
동기 블로킹을 간단하게 설명하자면 클라이언트가 서버를 호출하고 블로킹 때문에
서버가 클라이언트의 제어를 가져가고 클라이언트는 반환값을 기다린다.
이런 시스템은 요청이 수백 개 이상 들어올 때 성능에 문제가 생긴다
이방식은 이전 작업이 완료되어야 다음 작업을 진행할 수 있다.
서버가 작업하는 동안 클라이언트는 아무것도 하지 못하고 대기하고 있어야 한다.
클라이언트가 일을 하지 않고 노는 시간이 생기므로 비효율적

비동기 논블로킹을 보면 동기 블로킹과 방식이 다르다.
클라이언트가 서버를 호출하는 것까지는 같다.
서버가 제어를 가져가서 논블로킹 때문에 다시 클라이언트에 반환한다
비동기 때문에 클라이언트는 반환값을 기다리지 않는다.
클라이언트와 서버도 서로 할 일을 하고 서버는 일끝 나면 콜백으로 클라이언트 부른다.
클라이언트가 노는 시간이 없어 효율적
동기 블로킹은 기존 spring mvc이고 비동기 논블로킹은 spring reactive 랑 동작방식이 같다.
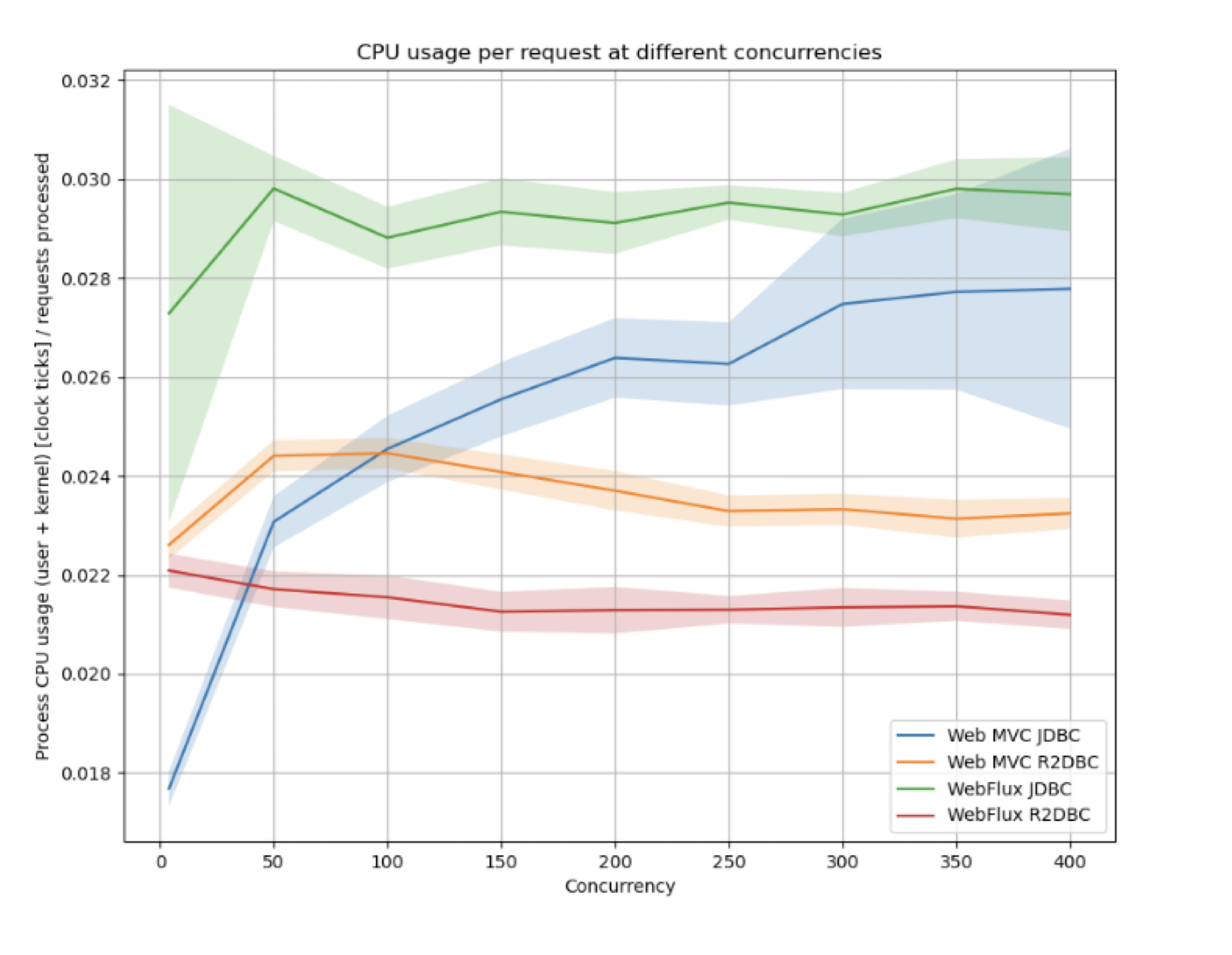
앞에서 말했던 것처럼 서버의 성능이 충분히 좋고 메모리 용량도 충분하다면
동기 방식으로 구현한 서비스도 큰 문제없이 요청을 처리할 수 있지만
문제는 서비스가 성장해서 훨씬 많은 사용자가 접속할 때 발생한다.
특히 동기 방식으로는 특정 시간대 혹은 갑자기 짧은 시간에 많은 사용자가 몰릴 때
이를 제대로 처리하기 어려울 수 있다.
낮은 동시성에서는 Web MVC and JDBC 가 유리 하지만 high concurrency에서는 R2DBC 가 유리하다.
참고로 R2DBC는 reactvie를 relational database에서 쓰기 위한 api
리액티브 스택에서는 비동기-논블로킹 형태로 개발하는 것이 자연스럽고 최적의 성능을 보여준다.
비동기 논블로킹은 항상 좋은 것일까
일반적으로 리액티브 논블로킹 응용 프로그램의 실행 속도가 향상되지 않습니다.
비동기 방식의 아키텍처가 효과를 보기 위해서는 서비스의 스케일이 일정 규모 이상으로 커져야 한다는 이슈가 있습니다. 100명 정도가 접속하는 서비스라면 비동기로 구현하나 동기로 구현하나 큰 차이가 없을 수 있습니다. 서버의 성능이 충분히 좋고 메모리 용량도 충분하다면 동기 방식으로 구현한 서비스도 큰 문제없이 요청을 처리할 수 있을 것.
문제는 서비스가 성장해서 훨씬 많은 사용자가 접속할 때 발생합니다. 특히 동기 방식으로는 특정 시간대 혹은 갑자기 짧은 시간에 많은 사용자가 몰릴 때 이를 제대로 처리하기 어려울 수 있습니다. 이런 종류의 이슈는 비동기 방식을 사용하면 수월하게 해결할 수 있죠. — 네티개발자
리액티브 논블로킹의 주요 예상 이점은 고정된 적은 수의 스레드와 적은 메모리로 확장할 수 있다.
예측 가능한 방식으로 확장되기 때문에 부하가 걸린 경우에도 응용 프로그램의 탄력성이 높아진다.
비동기 논블로킹 방식은 대개 단일 스레드에서 다중 요청을 처리하므로,
블로킹 방식에 비해 더 적은 메모리와 CPU 리소스를 사용하여 높은 처리량을 달성할 수 있다.
그러나 비동기 논블로킹 방식은 단점이 있다
디버깅이 어렵다.
-> 동기식 보다 얼마나 어렵겠어 생각하면 오산.....
-> 결과값이 찍히지 않는 것은 물론이고 테스트도 정말 다르다
비동기 논블로킹 방식이 블로킹 방식보다 더 나은 처리량과 응답 시간을 제공할 수 있다.
Reactive를 하면서 만났던 이슈들에 대해 간단히(?) 정리해 보자~
초기 이슈 1 - h2 db 가 설정을 추가해도 h2 Web console이 안 뜬다
- h2는 서블릿으로 서버를 띄워서 netty 기반으로 있는 어플리케이션에서 띄우려면 수동으로 띄워야 함
초기 이슈 2 - Insert 시 update 되는 이슈
- id로 필드 선언 해놓은 것을 임의로 값을 넣고 insert 하려고 하면 update로 전환돼서 에러
ex> 임의의 테이블에 id 값을 직접 넣어줬어야 했는데,
id에 값을 세팅하고 insert 시 update 문이 자동으로 실행하고 해당 키가 없어서 update 할 수 없다고 에러 - @query로 insert 추가
- JPA에서 query insert 시 update 구분하는 것은 아래와 같이 entity.isNew로 insert 인지 update 인지 구분한다.
- 만약 구현하고 싶다면 Persistable을 implements 받아서 isNew 되는 조건을 만족시키면 된다.
- 솔직히 이건 JPA 이슈인데 이렇게 써본 적이 없어서 reactvie 이슈인 줄 알았다..
-
public interface Persistable<ID> { /** * Returns the id of the entity. * *@returnthe id. Can be {@literalnull}. */ @Nullable ID getId(); /** * Returns if the {@codePersistable} is new or was persisted already. * *@returnif {@literaltrue} the object is new. */ boolean isNew(); }
public <S extends T> Mono<S> save(S objectToSave) {
Assert.notNull(objectToSave, "Object to save must not be null!");
if (this.entity.isNew(objectToSave)) {
return this.entityOperations.insert(objectToSave);
}
return this.entityOperations.update(objectToSave);
}
이렇게 이슈를 처리하고
내 멋대로(기존 전형적인 자바식으로) find와 insert 를 만들고 테스트를 했는데.....
find 와 insert 가 기존 jdbc 보다 더 느렸다.
분명 reactive는 빠르다고 했는데 왜 이렇게 느린 거 같지..
쓰는 내가 문제겠지 하고 튜닝을 시작했다.

find 할 때 초기 버전 소스
Flux<Stack> stackFlux = stackRepository.findByProject();
List<StackResponseVo> list = new ArrayList<>();
stackFlux.filter(stack -> stackReadVo.getScreenIds().contains(stack.getScreenId()))
.subscribe(stack -> {
StackResponseVo stackResponseVo = new StackResponseVo(stack);
callStackRepository.findById(stack.getCallStackHash()).subscribe(
callStack -> stackResponseVo.setCallStack(callStack.getCallStack()));
list.add(stackResponseVo);
});- 파라미터와 필터 값으로 stack 데이터를 추출한다. (stack 1 - * callstack)
- stack에서 받아온 데이터로 callStackHash를 알 수 있고 그 키로 callStackTrace를 조회한다.
- 받아온 데이터를 vo에 담에서 List에 더한다
문제는 해당 api 하나 호출하는데 20초 정도 걸렸다.
이유는…?
- 테이블 자체에 양이 너무 많아서 db에서 직접 조회하는 것도 시간이 걸린다.
- api에서 늦게 처리가 된다.
이슈 1. 테이블 자체에 양이 너무 많아서 db에서 직접 조회하는 것도 시간이 걸린다.
-> 파티셔닝을 하자!!!!
-> db는 h2로 해야 한다. (메모리가 아니라 파일로 저장)
-> front에서 특정파라미터에 날짜를 받으면 그 파라미터를 db 명으로 커넥션을 생성(h2는 파티셔닝 안됨)
해결 1. R2dbc에서 multidatabase 사용하기
R2dbcEntityTemplate 이걸로 sql을 직접 만들어서 사용했다.
보통 이렇게 하지 않고 제공해 주는 Insert 나 select를 사용한다
spring data 도 지원해 주고 복잡한 퀴리는 없어서 따로 쿼리를 쓰지 않았는데…
r2dbc를 사용하기 위해서 ReactiveCrudRepository를 상속받아서 사용했다.
- 날짜 시간단위로 테이블을 파티셔닝을 하면 테이블 이름이 동적으로 달라지기 때문에 R2dbcEntityTemplate로
써야만 했다….😡
https://docs.spring.io/spring-data/r2dbc/docs/current/reference/html/#r2dbc.multiple-databases
예시가 있는데 내가 구성하려고 하는 환경과는 맞지 않았다.
[r2dbc에서 boot up시 Multidata base 동작하는 작업]
- AbstractRoutingConnectionFactory을 리턴하는 connectionFactory bean 정의
AbstractRoutingConnectionFactory는 R2DBC 모듈에 포함되어 있는 클래스.
클래스로써, 여러 DataSource를 등록하고 특정 상황에 맞게 원하는 DataSource를 사용할 수 있도록 추상화한 클래스
참고로 spring-jdbc 모듈에서는 AbstractRoutingDataSource 로 구현
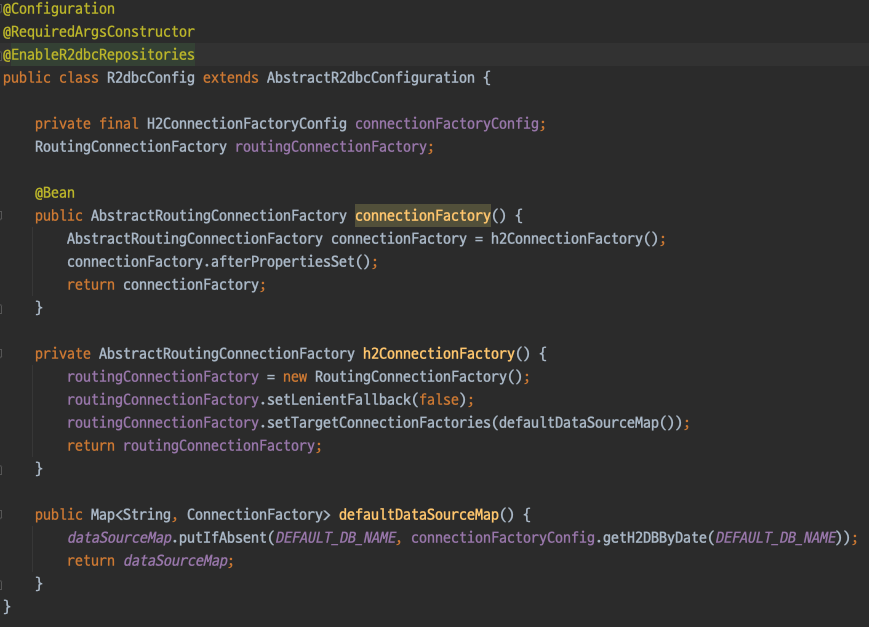
2. connectionFactory 를 만들 때
구현한 RoutingConnectionFactory 구현체로 만든다.
@Slf4j
@RequiredArgsConstructor
public class RoutingConnectionFactory extends AbstractRoutingConnectionFactory {
static final class H2ConnectionFactoryMetadata implements ConnectionFactoryMetadata {
static final H2ConnectionFactoryMetadata INSTANCE = new H2ConnectionFactoryMetadata();
private H2ConnectionFactoryMetadata() {
}
@Override
public String getName() {
return DEFAULT_DB_NAME;
}
}
@Override
protected Mono<Object> determineCurrentLookupKey() {
return Mono
.deferContextual(Mono::just)
.filter(it -> it.hasKey(DB_FILE_NAME))
.map(it -> it.get(DB_FILE_NAME))
.defaultIfEmpty(DEFAULT_DB_NAME);
}
@Override
public ConnectionFactoryMetadata getMetadata() {
return H2ConnectionFactoryMetadata.INSTANCE;
}
}3. RoutingConnectionFactory는 오버라이드 받아서 상황에 맞게
Key를 반환하도록 구현할 수 있다. 이때, Mono deferContextual 으로 ContextView ContextView에 있는 값을 가져온다.
4. determineCurrentLookupKey determineCurrentLookupKey는 메소드 내부에서 쿼리 호출시마다 동적으로 결정된다.
return 되는 String 결괏값에 해당되는 datasource를 실행한다.
5. 처음에 bootup시 ContextView 에 해당하는 값이 없어서 defaultIfEmpty 로 값을 설정
⇒ default를 지정하고, routing 전략을 사용한다면 Datasource를 선택하여 사용할 수 있게 되는 것
[db 조회시 내부적으로 동작되는 작업]
AbstractRoutingConnectionFactory 를 구현한 RoutingConnectionFactory 에서
determineCurrentLookupKey 로 context에서 해당되는 키를 찾아온다
ContextView 에 DB_FILE_NAME 로 저장되어있는걸 가져온다
- determineCurrentLookupKey 에서 꺼내는 기준은 dataSource 에 셋팅 했던 키 를 기준으로 한다
template.getDatabaseClient()
.sql(Sql)
.bind("project_id", id)
.map(MAPPING_FUNCTION)
.all()
.contextWrite(getContext());[r2dbc에서 web요청시 filter 에서 일어나는 작업]
- 읽어온 정보를 Map<String, ConnectionFactory> dataSourceMap 에 저장
- 만들어지는 dataSource 마다 새로 넣어줘야 한다(날짜별)
- ContextView 에 저장 한다
- db 조회를 할때 AbstractRoutingConnectionFactory 를 구현한 RoutingConnectionFactory 에서 determineCurrentLookupKey 로 context에서 해당되는 키를 찾아온다
@Component
@RequiredArgsConstructor
public class ProjectWebFilter implements WebFilter {
public static Map<String, ConnectionFactory> dataSourceMap = new ConcurrentHashMap<>();
private final H2ConnectionFactoryConfig connectionFactoryConfig;
private final R2dbcConfig r2dbcConfig;
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
List<String> startDate = exchange.getRequest().getHeaders().get(START_DATE_TIME);
if(startDate == null || startDate.size() != 1) {
return chain.filter(exchange);
}
String dbFileName = DateUtil.getTodayDateByTimeStamp(Long.valueOf(startDate.get(0)));
dataSourceMap.putIfAbsent(dbFileName, connectionFactoryConfig.getH2DBByDate(dbFileName));
r2dbcConfig.h2ConnectionFactorys();
return chain
.filter(exchange)
.contextWrite(ctx -> ctx.put(DB_FILE_NAME, dbFileName));
}
}
한번 그냥 쓱 보면 이해가 안간다.
간단하게 정리 해보자면
1. AbstractRoutingConnectionFactory, AbstractR2dbcConfiguration 설정한다.
2. webfilter 에서 받아온 값으로 context 를 세팅한다.(비지니스에 맞게 변형 가능)
3. db를 조회할때 context에 있는 값으로 db조회를 동적으로 한다.
여기서 나오는 Context란?
Reactive programming 에서는 스레드를 사용해서 거의 동시에 실행되는 비동기 시퀸스를 처리할 수 있다.
execution 은 쉽게 일어나고 다른 스레드로 넘어가는 것도 흔하다.
ThreadLocal 쓰레드 단위로 로컬 변수를 할당하는 기능이다. 이 기능은 ThreadLocal 클래스를 통해서 제공
쓰레드1에서 실행할 경우 관련 값이 쓰레드1에 저장되고 쓰레드2에서 실행할 경우 쓰레드2에 저장된다는 점이다.
ThreadLocal에 의존하는 라이브러리는 reactor 모델을 사용하면 새로운 도전에 마주친다.
최악은 잘못동작하거나 실패할 수 있다.
reactor 버전 3.1.0 부터 ThreadLocal 과 비슷하지만 thread 대신 flux 나 mono 에 적용할수 있는
고급기능을 제공한다. 이걸 context 라고 한다
좀 복잡해 보이는데 복잡한 게 맞다.
다른 예제 소스에서는 대부분
보통은 datasource를 두 개를 명시적으로 선언 하고
databaseSource에 따른 repository 경로도 따로 설정해서 쓴다.
그러면 이상이 있을 수가 없다. 왜냐 두 개만 명시적으로 쓰니깐.
하지만 내가 한 방식은 datasource가 명시적으로 선언된 것이 아니라 dynamic하게 만들어지기 때문에
repository를 쓸 때마다 어떤 datasource에서 쓸 건지 명시해줘야 한다.
그래서 이것을 해결해 주기 위해서 context를 이용한다. determineCurrentLookupKey 는
context에서 key의 값이 있냐 없냐에 따라 나뉘기 때문에
contextWrite(it -> it.delete(DB_FILE_NAME).putAll(getCallStackContext().readOnly())));
이런 식으로 쿼리를 날릴 때 어떤 db를 쓸 건지 확인하고 실행했다.
r2dbc에서 datasource를 두개 이상 동적으로 쓸 때에만 이 예시를 보고
두 개나 혹은 datebaseSource 개수가 정해졌다면 굳이 이 예시를 따라 할 필요가 없다.
이슈2. api 에서 늦게 처리된다.
- reactive를 동기식으로 짜고 있으니깐 느렸다.
다시 소스를 가져와보면
- stack 을 처리하는 stackFlux
- 가져온 stack에서 callStack을 처리하는 callStackFlux
Flux<Stack> stackFlux = stackRepository.findByProject();
List<StackResponseVo> list = new ArrayList<>();
stackFlux.filter(stack -> stackReadVo.getScreenIds().contains(stack.getScreenId()))
.subscribe(stack -> {
StackResponseVo stackResponseVo = new StackResponseVo(stack);
callStackRepository.findById(stack.getCallStackHash()).subscribe(
callStack -> stackResponseVo.setCallStack(callStack.getCallStack()));
list.add(stackResponseVo);
});
해결 : 한꺼번에 zip 하는 Flux를 만들어서 처리
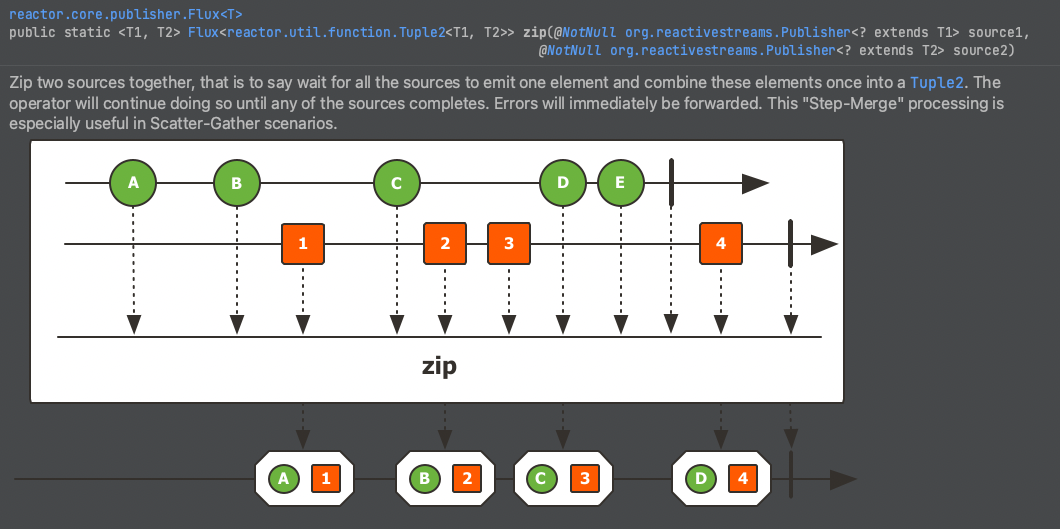
public Flux<StackResponseVo> findStack(StackReadVo stackReadVo) {
Flux<Stack> stackFlux = stackRepository.findByStackReadVo();
Flux<CallStack> callStackFlux = stackFlux
.flatMap(stack -> return callStackRepository.findById());
return Flux.zip(stackFlux, callStackFlux)
.flatMap(tuple -> Flux.just(new StackResponseVo(tuple.getT1(), tuple.getT2())));
}
문제는 Insert 도 느리다.
아니 만든 건 find, insert 밖에 없는데 왜 이렇게 빵빵 터지는지...
솔직히 이때부터 롤백하고 싶었는데 너무 멀리와서 꾸역꾸역 한거같다.
[insert의 초기 소스]
stackVo.getData().stream()
.collect(Collectors.groupingBy(StackDataVo::get~~~))
.forEach((key, stackDataVoList) -> {
stackDataVoList.stream()
.forEach(stackDataVo -> {
stack.setSomeThing();
}
});
save(stack, callStack);
});이슈
- forEach를 돌면서 saveStack 이 실행되고 mono type이 여러 개가 나온다.
해결방법
- monoType 이 나올 때마다 subscribe 를 한다
-> monoType 이 나올때 마다 처리하는 것은 동기식 프로그램이랑 다를 바가 없다 - mono type을 올 때마다 처리하지 않고 list에 쌓아두었다가 Flux.merge로 실행한다.
→ 이걸 생각하고 구현하는 게 오래 걸림
이론상 하나하나 생길 때마다subscribe 하는것 보다 비동기식으로 save 준비가 끝난
mono type부터 맞다고 생각해서 해당 부분 적용했다.
하지만 merge 할 때 주의할 점은 두 객체 중 하나라도 null 이면 안된다.
내가 적용한 사례는 하나가 null 이 될수 있어서
Flux.merge가 아니라 각각 subscribe 를 했다.
다른 예제 소스를 보면 대부분 WebFlux 예제라 Controller에서 subscribe를 안 하고
mono 나 flux 객체로 반환하고 끝인데 나는 똑같이 했는데 안되었다.
이유를 한참 찾았는데, WebFlux에서 controller에서 mono 나 flux 객체를 반환하면
나중에 subscribe해주는 부분이 있는데, 나는 rabbitmq에서 consume 하는 거라
subscribe를 직접 호출해줘야 했다.
하지만 여기서 또 문제가 발생했는데..........
rabbitmq에서 subscirbe를 하니깐 consume 속도가 미친 듯이 올라갔다.
이게 왜 문제일까?
처음에는 '내가 만든 게 잘 만들어져서 consume 이 잘되는구나'
생각을 했지만 아주 단단한 착각이었다 ㅠㅠㅠ

consume은 되는데 1000건이 저장되야 하는데 500건만 저장되는 이슈가 발생했다!!
여기서 하나 문제
rabbitmq에서 spring 이 consume을 할 때는 정확하게 어떤 타이밍일까?
이 타이밍 문제가 위에 저장 이슈와 관련이 있었다.
그때는 난 몰랐다... rabbitmq로 발표 까지 했는데... ㅜㅜ
gpt 선생님에게 물어보니 다음과 같이 말한다

rabbitmq에서 subscirbe를 하니깐 consume 속도가 미친 듯이 올랐던 이유는
queue에서 메시지를 받아서 mq 보스 스레드가 한번에 하나씩 메세지를 처리해야하는데
reactive는 비동기라서 mq 보스 스레드가 바로 종료되고 mq 부하 스레드에게 맡긴다.
reactive는 subscirbe할때 보스 스레드가 처리하는게 아니라 부하스레드에게 넘긴다
그래서 메세지 처리가 완료되었다라고 생각하고 mq 보스 스레드가 다음 메시지를 가져온다.
그렇지만 mq 부하 스레드는 아직 일처리가 끝나지 않았다.
그래서 consume 속도가 빠르게 처리되었지만 어플리케이션 단에서는 처리가 안되고 날아갔다.
보스스레드, 부하스레드는 구분을 위한 예시!!
지금에서야 원인을 알고 원인을 통해 결과를 알수 있었는데
저 이슈가 발생했을때는 위에 내용을 찾아내는 게 무척이나 어려웠는데
spring boot admin을 붙여서 메모리가 줄어들지 않는 현상을 보고
메모리가 줄어들지 않을때 힙덤프를 떠서 유추 했다.
그래서 이결 해결하기 위해 block을 걸어서 동기로 만들었는데 뭔가 다른 방법이 있을 것 같았다.
Bulk insert
데이터의 특성상 하나의 mq 메세지에 180건 정도 insert raw가 일어나는 상황이었다.
한꺼번에 insert 하려고 제공해 주는 saveAll을 썼는데 이게 너무 느렸었다.
그래서 saveAll의 상세 구현을 살펴보니 다음과 같았다.

하나의 쿼리로 날라가는게 아니라 raw 하나하나 save 해서
r2dbcEntityTemplate 를 사용해서 insert 가 bluk로 들어갈 수 있게
sql문을 직접 만들어줘서 하나의 쿼리만 날아가게 수정했다.
이 글을 써야겠다 맘먹은 계기이기도 한데 여기서 본 아래 문구가 공감이 많이 갔다.
검색을 위한 데이터 다루기 | 우아한형제들 기술블로그
{{item.name}} 안녕하세요. 우아한형제들 검색개발팀 정철입니다. 배달의민족 검색시스템에서 검색에 사용되는 데이터를 적재하면서 경험했던 어려움과 해결했던 방법을 공유하고자 합니다. 검색
techblog.woowahan.com
To optimize insert speed, combine many small operations into a single large operation. Ideally, you make a single connection, send the data for many new rows at once, and delay all index updates and consistency checking until the very end.
출처 : https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.htmlinsert 성능을 높이기 위해서는 작은 여러 연산을 큰 하나의 연산으로 만들어라. 라는 말을 위의 mysql doc에서 볼 수 있듯이 그렇게 배웠고 그렇게 개발을 진행했었습니다.
정리해 보자면
reactive에서 mono, flux 리턴
-> 실행이 안돼서 subscribe를 추가
-> subscribe 때문에 별도 스레드가 처리하기 전 메세지를 받아옴.
-> block(동기식)으로 수정
-> saveAll을 r2dbcEntityTemplate 를 사용해 bluk insert로 수정
-> subscribe로 원복
-> 정상동작
결국 부하스레드에게 맡기고 부하스레드의 일처리속도를 올려서 해결한 케이스이다.
결과
- db에 insert 시에 2초에 2천 건 정도 insert 되는 것을 확인했다.
- 하루에 insert 만 100만 이상이 많았는데 급격하게 줄었다.
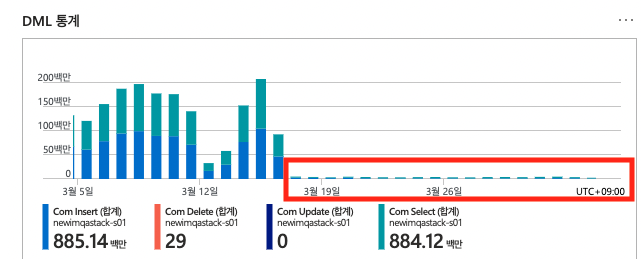
하지만 지금도 여전히 어플리케이션에 감당할 수 없는 데이터가 들어오면
내가 만든건 메모리에 테이터를 쌓다가 터진다.
이럴꺼면 차라리 동기식으로 하고 mq에 데이터를 쌓는게 맞는것 같다.
이번에 비동기를 도입하면서 느낀 점은
아직 구시대적 마인드를 지녀서 그런지 몰라도 트레픽이 많아지면
스레드가 감당 못해서 메모리가 올라가면서 터지는 것보다 어디 한쪽에서는
잘 보이게 처리되지 않은 데이터를 보관해야 하는거 아닌가 싶다.
mq도 비동기인데 reactive도 비동기니깐 데이터가 많아지면
병목이 생기고 그 부분을 scale up 하던가 out 하던가 해야 하는데
다 메모리에 밀어 넣으니 모니터링 시스템을 딱 봤을 때 이상 없이 돌아가는 것처럼
보이는데 어차피 mq로 비동기를 챙기고 있었다면 데이터를 처리하는 어플리케이션에서는
굳이 비동기가 필요했을까라는 느낌도 있다.
또 유지보수가 어려운 것도 뭔가 다시 도입하기에 꺼려지는 이유다.
jdk 21에서는 가상스레드를 만들어서 알아서 해준다고 하니 기다려봐야겠다.
'개발' 카테고리의 다른 글
| 자바스크립트 event loop와 scope chain 이해 (1) | 2023.10.04 |
|---|---|
| java 에서 백분위수 빠르게 구하는 방법 (0) | 2023.08.01 |
| Azure Virtual Machines 설명 (0) | 2023.03.29 |
| Azure의 핵심 아키텍처 구성 요소 간단 정리 (0) | 2023.03.24 |
| pm2 다운 node max-memory-restart 메모리 값 설정 (3) | 2023.01.19 |


